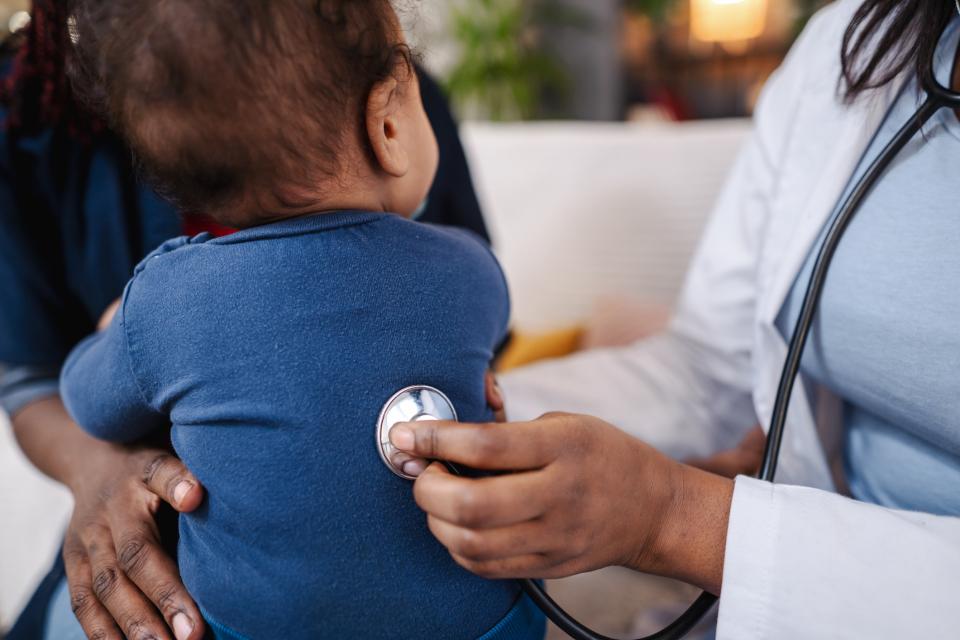
Medical algorithms trained on adult data may be unreliable for evaluating young patients. But children’s records present complex quandaries for AI, especially around equity and consent.
A model trained on thousands of images in medical textbooks and journal articles found that dark skin tones are underrepresented in materials that teach doctors to recognize disease.
There’s a faster, cheaper way to train large language models
Large language models have been dominated by big tech companies because they require extensive, expensive pretraining. Enter Sophia, a new optimization method developed by Stanford computer scientists.